Paxos是出了名的难懂,而Raft正是为了探索一种更易于理解的一致性算法而产生的。它的首要设计目的就是易于理解,所以在选主的冲突处理等方式上它都选择了非常简单明了的解决方案。
Raft算法
Raft 算法从多副本状态机的角度提出,用于管理多副本状态机的日志复制。Raft把一致性问题分解为了多个子问题
- Leader选举 Leader election
- 日志同步 log replication
- 安全性 safety
- 日志压缩 log compaction (可选)
- 成员变更 membership change(可选)
Q: 为什么日志复制就能够保证集群状态一致?
A: 因为日志可以是集群的指令,比如说 X <- 3这条日志,就是把3赋给X这个值,集群如果按照某种手段处理这些日志,并且保证日志是一致的,那么就可以得到一致的状态。
角色
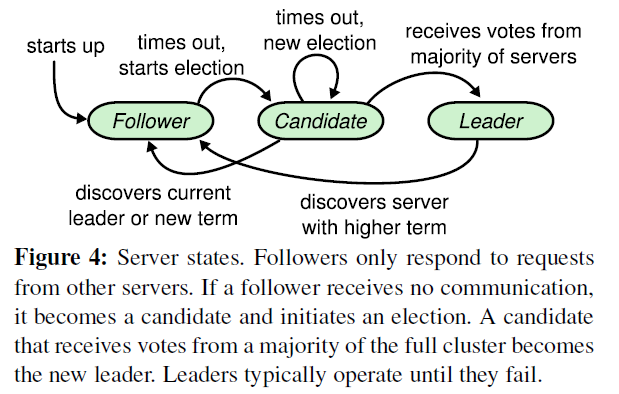
raft降系统中的角色分为 Leader、Follower、Candidate
- Leader 接收客户端请求,并向Follower同步请求日志,当日志同步到大多数节点上后告诉Follower提交日志。
- Follower 接收并持久化 Leader 同步的日志。
- Candidate 选举的临时角色
集群默认只存在一位 Leader,其余都是Follower。Leader 会定时发送 心跳 告诉 Follower 保持Leader的统治地位。如果 Follower 超过一定的时间未收到心跳 (一般为150~300ms) ,那么 Follower 就会转为 Candidate 并发起一次选举,如果它获得了大多数的投票则自动成为 Leader。
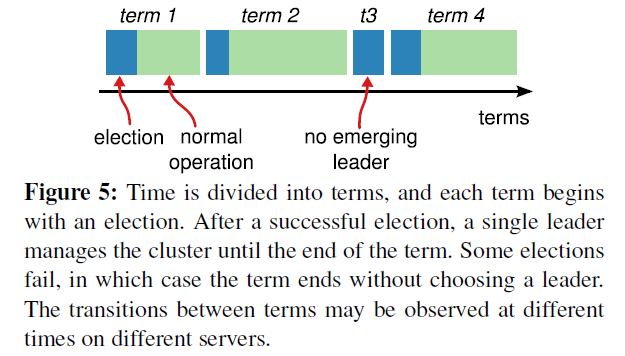
raft算法把时间分为一段段的任期(term) ,每一个 term 的开始都是Leader选举,在成功选举Leader之后,Leader会在term之内管理整个集群。如果Leader选举失败,则该term就会因为没有leader选举结束。