MySQL知识全文。
MySQL知识图谱全篇
目录
MySQL基础知识
基本结构
MySQL 是一个典型的CS结构。我们一般所说的 MySQL 都是它的 Server 结构。Server结构又是什么东西呢?我们应该都在自己的开发机器上安装了 MySQL , 一个比较简单的安装办法就是在MySQL的官网下载包,然后解压之后运行一个 .sh 文件去启动一个 MySQL 进程,这个MySQL进程就是 Server。而 Client 可以是执行 mysql -h localhost -uroot -p 去运行SQL的程序,也可以是自己书写去连接MySQL的代码所运行的程序。
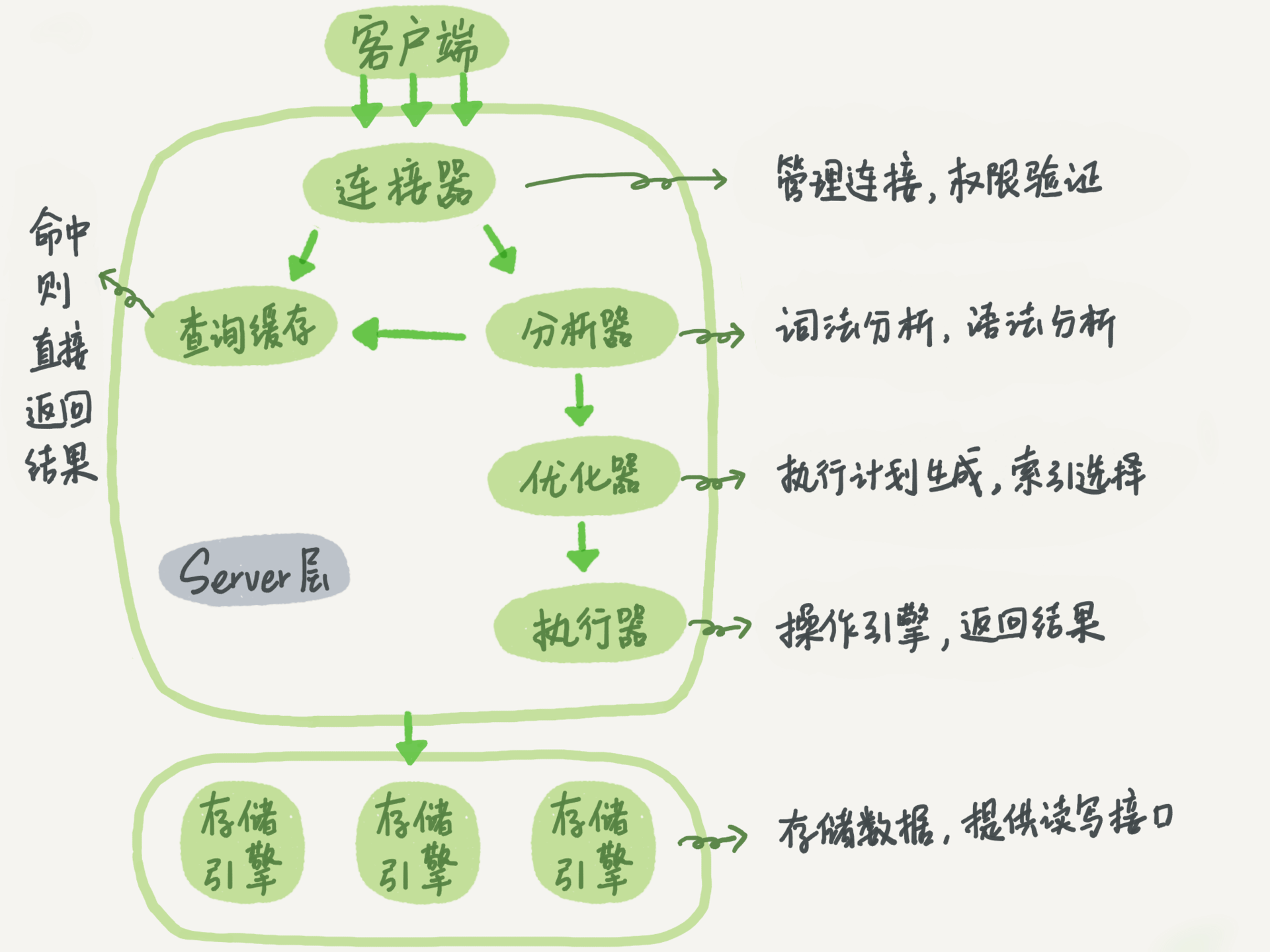
图片取自极客时间 MySQL 实战 45 讲
Server部分又可以更加具体的分为Server层和存储引擎层。MySQL是一个插件式的程序,它可以有不同的存储引擎,但是在处理数据的时候又会有相同的处理过程,因此MySQL把它分为了两个部分,Server层统一处理,存储引擎可以相互替换。
Server层包括了连接器、查询缓存、分析器、优化器、执行器,涵盖了MySQL的绝大部分核心功能,以及所有的内置函数(日期、时间、数学、加密等),所有跨存储引擎的功能都在这里实现,比如说存储过程、触发器、视图等。
储存引擎则负责数据的存储和提取。它是插件式的,可以相互替换,支持InnoDB、MyISAM等。
存储引擎
存储引擎负责数据的存储和提取,MySQL支持多种存储引擎,你甚至可以自行书写一个存储引擎,只要它符合MySQL的协议即可,具体协议已可以在 GitHub 找到,通过注释也可以看的很清楚,这里就不做过多的说明。
接下来一下我们常用的几个存储引擎: InnoDB、MyISAM。InnoDB是MySQL5.1版本之后的默认存储引擎,它相对于MyISAM来说最大的特点就是支持事务,以及支持更细粒度的锁。
MySQL存储引擎的设计让我想到设计其余组件的时候,可以把数据操作和数据存储分离开来。这样就可以做到多种数据存储互相替换。这貌似是软件工程的基本思路了,所以的东西都提供接口,架构师设计接口,普通程序猿负责接口的实现,核心程序员负责数据操作部分的实现。哎,什么时候才可以到架构师的水平。。。
数据类型
MySQL的数据类型分为四大类:整型、浮点型、字符串、日期。
- 整型
TINYINT、SMALLINT、MEDIUNINT、INT、BIGINT分别暂用8、16、24、32、64。INT(10) 后面的10表示显示字符的个数,没有实际的意义,但是当与UNSIGNED ZEROFILL配合使用才有实际意义,例如,数据类型INT(3),属性为UNSIGNED ZEROFILL,如果插入的数据为3的话,实际存储的数据为003
| 类型 | 占用字节 | 备注 |
|---|---|---|
| TINYINT | $ 2^{3} $ | TINYINT(1)用来表示Boolean |
| SMALLINT | $ 2^{4} $ | |
| MEDIUNINT | \(\lceil \frac{(2^{4}+2^{5})}2 \rceil\) | |
| INT | $ 2^{5} $ | |
| BIGINT | $ 2^{6} $ |
- 浮点数
FLOAT、DOUBLE、DECIMAL。其中DECIMAL使用字符串进行处理,能够精确存储小数,相对于FLOAT、DOUBLE来说效率会低一些,但是在存储账户余额等精度要求特别高的情况下会特别有用。浮点数等都可以指定列宽,比如说DOUBLE(5,3)表示总共可以存储5位,其中小数部分存储3位。
- 字符串
CHAR、VARCHAR、TEXT、BLOB。其中VARCHAR用于存储可变长度的字符串,相比于定长的CHAR更节省空间但也相应的会增加磁盘碎片。TEXT、BLOB都是无限长度的字符串,但是一般避免使用,它们在查询的时候会使用临时表,造成严重的性能开销
- 日期
比较常用的有year、time、date、datetime、timestamp等,datetime保存从1000年到9999年的时间,精度位秒,使用8字节的存储空间,与时区无关。timestamp和UNIX的时间戳相同,保存从1970年1月1日午夜到2038年的时间,精度到秒,使用四个字节的存储空间,并且与时区相关。date只保存年月日。
应用场景:尽量使用timestamp,相比于datetime它有着更高的空间效率。
索引
索引是什么
索引是数据库中一个排序的数据结构,用于协助快速查询、更新数据库表内容。
为什么需要索引
当表数据越来越大的时候,需要一种有效的手段来帮助我们快速查找一些内容(更新也需要先查找)。索引就和书籍的目录是一个道理,目录编码了章节和页码,当我们需要找某个特定章节的时候就可以根据目录去找到页码,实现快速定位而不需要一页一页取翻页确定。
MySQL索引名词解释
- 聚簇索引、非聚簇索引。看索引是不是聚簇索引只需要看行数据、索引数据是否是同时存在一个索引的数据结构中即可,在InnoDB中,主键使用的索引就是聚簇索引,而其余索引则是非聚簇索引。比如说一个表
create table users(id int primary key,age int, name varchar(25), index(age))中存在两个索引。第一个默认的就是主键索引,它使用ID进行数据划分,同时在BTree树的叶子结点保存行数据,这个索引就是聚簇索引,还有另外一个索引就是age这个非聚簇索引,它的叶子结点不保存数据,而是保存主键的值,这种行数据、索引数据不在一个数据结构中的就认为是非聚簇索引。在MyISAM中,主键索引和其它索引使用的都是非聚簇索引,叶子结点保存的是地址 - 索引种类:主键索引、组合索引、唯一索引、全文索引、普通索引等。
- 索引的数据结构:MySQL主要的索引有:
FULLTEXT全文索引、HASH哈希索引、BTREEB树索引、RTREE空间数据索引等。 - 索引覆盖:索引覆盖实际上就是在查询语句时是否完全使用某一个索引的字段。比如说我们之前的
create table users(id int primary key,age int, name varchar(25), index(age))表中,如果我们运行select id,age from users where age = 10;语句,可以直接使用age索引就能够查询出结果,这个时候就认为是索引覆盖,否则查询select name from users where age = 10这个时候虽然会使用age索引,但是还是需要再次根据ID回表查询主键索引,这样就不能称为索引覆盖。 - 回表查询:回表查询在刚刚索引覆盖就已经提到了,也就是说先通过非聚簇索引查询到主键,再通过主键聚簇索引查询到对应数据的过程就称为回表查询。
- 索引下推:索引下推就是把索引原本在Server层做的事情交给存储引擎层去做。索引下推可以减少回表次数,可以减少存储引擎上传到Server层的数据。
索引问题
- 索引的数据结构
FULLTEXT索引采用倒排索引,在5.7.6版本及以后,MySQL内置了ngram全文解析器。
HASH索引采用HASH函数作为主要的工具
BTTRE索引采用B+树作为底层结构,B+数的特点如下:1. 非叶子结点不储存数据 2. 叶子节点以指针形式连接。 B+数的优点如下:B+ 树的磁盘读写代价更低
B+ 树内部非叶子节点本身并不存储数据,所以非叶子节点的存储代价相比 B 树就小的多。存储容量减少同时也缩小了占用盘块的数量,那么数据的聚集程度直接也影响了查询磁盘的次数。
B+ 树查询效率更加稳定
树高确定的前提下所有的数据都在叶子节点,那么无论怎么查询所有关键字查询的路径长度是固定的。
B+ 树对范围查询的支持更好
B+ 树所有数据都在叶子节点,非叶子节点都是索引,那么做范围查询的时候只需要扫描一遍叶子节点即可;而 B 树因为非叶子节点也保存数据,范围查询的时候要找到具体数据还需要进行一次中序遍历。
- 索引下推(ICP)是什么?什么情况下会触发索引下推?
官方文档。强烈建议大家观看官方文档,目前网络上大部分资料(包括我这里也是翻译)都是官方文档的翻译。
索引下推是Index Condition Pushdown,全意为索引条件下推,是MySQL针对索引从表中检索行情况下进行的专门优化,也就是
Select语句匹配到索引进行的优化。如果没有 ICP,存储引擎会遍历索引以定位基表中的行,并将它们返回给 MySQL 服务器,由 MySQL 服务器评估WHERE行的条件。启用 ICP 后,如果部分WHERE条件可以仅使用索引中的列进行评估,则 MySQL 服务器会推送这部分WHERE条件下降到存储引擎。然后,存储引擎通过使用索引条目来评估推送的索引条件,并且只有在满足这一条件时才从表中读取行。ICP可以减少存储引擎必须访问基表的次数和MySQL服务器必须访问存储引擎的次数。当查询语句满足以下情况下会触发索引下推:
- ICP用于 range, ref, eq_ref,和 ref_or_null访问方法时,并有必要访问完整的表时。
- ICP可用于InnoDB引擎和MyISAM引擎,包括分区表。
- 对于InnoDB引擎,ICP仅用于非聚簇索引。ICP的目标是减少全行读取的数量,从而减少I/O操作。对于 InnoDB聚簇索引,它已有完整的记录。在这种情况下使用ICP不会降低I/O,自然也不会使用索引下推。
- 在虚拟生成列上创建的非聚簇索引不支持ICP。InnoDB 支持虚拟生成列上的非聚簇索引。
- 引用子查询的条件无法下推。
- 引用存储函数的条件无法下推。存储引擎无法调用存储的函数。
- 触发条件查询时无法下推。
日志模块
MySQL有三大日志模块: redolog、undolog、binlog 他们各有各的作用,接下来我们就开始从 redolog 说说
redolog
redolog 保存着存储引擎对数据页的操作,是 InnoDB 特有的文件日志,被设计为固定大小、顺序写入的类循环队列的日志形式,用于保证MySQL的 crash-safe 能力。
我们都知道 redolog 被用在 update 等更新语句中,那么如果每次都需要更新数据页这是一个很大的性能开销,因为每一行都被存储引擎随机存储到数据页中。那么存不存在一种方法,能够兼顾性能的同时有保证安全呢?这就是MySQL的WAL技术,也就是 Write-Ahead Logging ,WAL技术的关键在于先写日志,再写磁盘,顺序写入 redolog 日志的开销会比随机写磁盘的I/O性能消耗小很多。
总体来说,当我们需要更新一条语句的时候,InnoDB 会先把记录(在某个数据页中做了什么改动)顺序写入磁盘中,并更新 BufferPool 的内存数据,这样就认为更新已经完成了。同时 InnoDB 会在某个恰当的时间把 BufferPool 的数据同步到磁盘中去。
redolog 也不是直接刷入磁盘的,它也就自己的缓存区,redolog buffer。
需要注意的是:
redolog也是日志文件哦,它保存在磁盘中!!!redolog是类循环队列的形式,它由N个文件组成一个循环队列,有两个点需要关注:WritePos CheckPoint。WritePos代表当前记录写入的位置,CheckPoint代表上次同步的位置。- 上文所说的把
BufferPool在某个恰当的时间同步到磁盘中的某个恰当的时间点指的是: 系统较为空闲的时候、redolog空间不足的时候(WritePos >= CheckPoint)、- 同步一般指的是把
BufferPool的数据同步到磁盘中,redolog一般在crash使用。
binglog
我们上面说到的 redolog 是 InnoDB 存储引擎的日志,那么在 Server 层有没有属于自己的日志呢?有,我们称为 binlog,它为MySQL提供归档能力。
binlog 与 redolog 有四点不同:
binlog是Server层的日志,redolog是存储引擎的日志binlog记录的是逻辑日志,也就是语句的原始逻辑,比如说给某个表的某个字段进行了修改。redolog记录的是物理日志,在某个数据页上做了什么改动binlog是追加写入的,redolog是循环写入的redolog作为异常宕机或者介质故障后的数据恢复使用;binlog作为恢复数据使用,主从复制搭建。
binlog 有三种文件记录模式
row记录每一行被修改的情况,包括原本的数据和之后的数据,一般使用rowstatement记录SQL语句mixed混合
日志的二阶段提交
上文提到了 binlog 和 redolog 分别属于两个部分的日志,那么它们是如何保证日志一致性的呢?如果在写完 redolog 准备写 binlog 的时候程序宕机了,那么是不是 redolog 有日志而 binlog 没有日志呢?会不会造成主库与从库的数据不一致呢?哎嘿,当然是不会的,这里就需要讲到日志的二阶段提交。
我们从一条 update t set n=2 where id = 1; 语句讲起,MySQL的处理流程
- 拿到
id=2的数据,如果BufferPool存在就直接拿,如果没有就从磁盘中找到对应的页数据并载入到BufferPool中 - 在
BufferPool的Data Page做 Update 操作,并把操作的物理数据页修改记录到redolog buffer中,并在未来的某个时间点同步到redolog中,此时redolog处于Prepare状态 - 写入
binlog - 提交事务,把
redolog设置为commit状态
为什么需要二阶段提交呢?
为了保证
redolog和binlog的一致性。我们提到redolog用于异常宕机的数据恢复,binlog用于主从复制,如果redolog、binlog数据不一致,就很可能存在主服务通过redolog恢复数据之后与使用binlog同步数据的从服务数据不一致
当前有三个阶段 1. prepare 2. 写入 binlog 3. commit
- 在写入
binlog时程序宕机了,这时redolog有一条处于prepare的数据,而binlog没有数据。在使用redolog恢复数据的时候会发现有一条prepare的记录,并且在binlog中找不到这一个事务的提交记录。就回滚这条redolog - 在3之前奔溃,这时
redolog和binlog都有数据,但是redolog的状态还是prepare。在使用redolog恢复数据的时候会发现有一条prepare的记录,并且在binlog中属于已提交的,那么就会修改redolog自动提交。
undolog
undolog 则记录了事务 rollback 所需要的信息。
undolog 的回滚有一个很重要的概念叫事务ID(tx_Id)。
undolog 如何存储多个版本的数据
Innodb在每一行中都会有一些隐藏的字段,比如说
DB_ROW_ID用来生成默认的聚簇索引,如果没有指定主键索引就会使用该字段创建。DB_TRX_ID用来表示操作这个数据的事务ID,也就是最后一次对该数据进行修改的事务ID。DB_ROLL_PTR回滚指针,指向这个记录的undolog日志而
undolog中也保存了这些行的信息。也就是说undolog通过回滚指针把数据行版本串联起来了,其中数据行就是链表的头节点,而每次有事务进行操作就相对于往undolog中插入头节点,并重新生成一个头节点给数据行。
为什么需要 undolog
因为在事务还未提交时,可能
redolog已经刷盘了,这个时候MySQL宕机了,这个时候依靠redolog恢复的我们发现这条日志还没有提交,我们就需要会滚这条日志,但是我们又不清楚redolog这个页面之前的记录是什么,这个时候就需要undolog来发挥作用
事务
什么是事务
事务就是保证一组数据库操作要不全部成功要不全部失败。
事务四大特性
原子性:事务操作要不全部成功要不完全失败。由 undolog 实现
一致性:一个事务的开始到结束都需要保证数据的完整性不被破坏。由 程序 + AID 实现
隔离性:数据库允许多个事务并发执行。由 undolog 和 MVCC 实现
持久性:数据事务一旦处理完成,对数据的修改便是永久的。由 redolog 实现
事务问题
当有多个事务并发执行的时候,就会出现特定的问题,比如说
- 脏读:事务A读到了事务B未提交的数据
- 幻读:事务A两次查询查询了某些行,其中第二次查找到了事务B已插入或者删除的行
- 可重复读:事务A两次查询了某些行,其中第二次查找到了事务B已修改的行数据
事务隔离级别
为了解决事务问题我们提出了事务隔离级别概念,目前有四个事务隔离级别,其中隔离级别依次提高
- 读未提交:事务A可以读到其余事务未提交的数据
- 读已提交:事务A可以读到其余事务已提交的数据,不能读到未提交的数据
- 可重复读:事务A在执行过程中看到的数据,就是事务开始时的数据
- 串行化:对同一行记录加读写锁,后一个访问的事务需要等待上一个事务提交
MVCC原理
MVCC是多版本并发控制器,是在并发访问数据库时,通过对数据进行版本控制从而解决锁问题
MVCC的两个核心点是 undolog 和 ReadView 读视图,其中 undolog 用来保护版本数据,ReadView 用来保存当前活跃的事务列表。
undolog 我们在上文已经讲解过了,现在我们重点分析一下读视图。
ReadView 就是事务进行快照度的时候生产出来的,在事务执行快照读的时候,会生成数据库系统的当前的快照,记录并维护系统当前活跃的事务ID。
ReadView 有三个重要属性:
trx_list未提交事务的ID列表up_limit_id记录trx_list列表中的最小事务IDlow_limit_id当前出现的最大事务ID+1
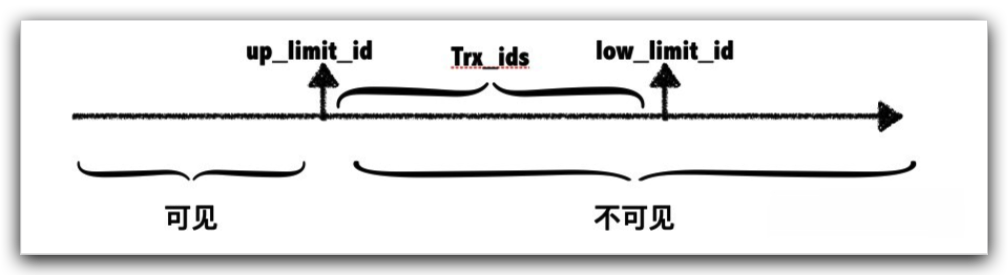
ReadView 遵循一个可见性算法,主要是将要被修改的数据的最新记录中的 DB_TRX_ID (即当前事务ID)取出来,与系统当前其他活跃事务的ID去对比(由 ReadView 维护),如果 DB_TRX_ID 跟 ReadView 的属性做了某些比较,不符合可见性,那就通过 DB_ROLL_PTR 回滚指针去取出 undoog 中的 DB_TRX_ID 再比较,即遍历链表的 DB_TRX_ID(从链首到链尾,即从最近的一次修改查起),直到找到满足特定条件的 DB_TRX_ID, 那么这个 DB_TRX_ID 所在的旧记录就是当前事务能看见的最新老版本。
因为 low_limit_id 和 trx_ids 要不就是 ReadView 创建之后的事务,要不就是当前未提交的事务ID集合。所以这两个都是不可见的。
Read Commited 和 Reaptable Read 的区别就在于你每次进行读操作的时候是否重新生成一个 ReadView 。如果重新生成 ReadView 的话,就代表每次读取的时候都会获得已提交的事务修改的内容,即 up_limit_id 会更新为最新的 trx_id ,也就是说是 Read Commited 隔离级别。
锁
基本SQL以及优化
面试题
索引面试题
- 索引数据结构
一般来说就是 BTree
其中BTree是B+树
Hash适用Hash表
FullText使用倒排索引
RTree使用空间数据索引
- 聚簇索引和非聚簇索引
聚簇索引包含数据,非聚簇索引不饱和数据
- 为什么适用B+树而不是B树
- 为了获取更加稳定的性能
- B+树更适合范围查找
- B+树可以减少磁盘I/O
- 非聚簇索引一定会回表吗
不一定,要看索引覆盖
- 索引下推是什么?
把原本在Server层做的事情下放到存储引擎去做
日志面试题
参考资料
- MySQL实战45讲 本人特别推荐大家购买学习
- 简书- MySQL核心知识
- 索引下堆
- 索引下堆官方文档
- 索引优势等
- 日志介绍

