介绍了Redis的基础知识,这应该是每个人都会的,不会有什么高深的东西,也不会介绍底层原理
基础知识
如何安装Redis
为什么需要使用Reids
因为传统的关系型数据库以及不能适用于所有场景了,比如APP首页的访问流量高峰场景,这种流量的并发级别很容易把数据库打穿,所以我们需要引入缓存中间件,市面上主要有两种缓存中间件:Redis 和 Memcached
为什么使用Redis
我们来介绍一下 Redis 和 Memcached。
Memcached
特点
- 在处理请求时采用多线程异步IO的方式,可以合理利用多核CPU的优势
- 功能简单,使用内存存储数据
- 失效的策略采用延迟失效,就是当再次使用数据时检查是否失效;
- 当容量存满时,会对缓存中的数据进行剔除,剔除时除了会对过期 key 进行清理,还会按 LRU 策略对数据进行剔除。
缺点:
- key 不能超过 250 个字节;
- value 不能超过 1M 字节;
- key 的最大失效时间是 30 天;
- 只支持 K-V 结构,不提供持久化和主从同步功能。
Reids
- 与 MC 不同的是,Redis 采用单线程模式处理请求。这样做的原因有 2 个:一个是因为采用了非阻塞的异步事件处理机制;另一个是缓存数据都是内存操作 IO 时间不会太长,单线程可以避免线程上下文切换产生的代价。
- Redis 支持持久化,所以 Redis 不仅仅可以用作缓存,也可以用作 NoSQL 数据库。
- 相比 MC,Redis 还有一个非常大的优势,就是除了 K-V 之外,还支持多种数据格式,例如 list、set、sorted set、hash 等。
- Redis 提供主从同步机制,以及 Cluster 集群部署能力,能够提供高可用服务。
Redis基础功能
我们从以下几个方面来介绍Redis的基础功能
- 基础数据结构
- 扩展功能
- 数据持久化方式
- key失效机制
- 淘汰策略
基础数据结构
Redis提供了一下五种基础数据结构:String 、List 、 Set 、 Hash 、 SortedSet,下面我们来分别介绍这几种数据结构吧
String
string就是最基本的k-v结构,在Redis的实现中直接存放在DB结构中的数据部分,如果直接使用String就可以实现绝大部份功能,甚至说所有功能,在真实开发环境中就有很多同事喜欢把数据Json格式话之后直接存放在Redis中,这里不说对错,每个团队都有每个团队的规范。
下面我们来看下Redis的适用场景:
- 计数器
- 共享用户Session
List
List是有序列表,比如通过List存储一些列表行为的数据,比如说文章列表等,基于Redis还可以实现简单的分页功能。
适用场景
- 简单的消息队列
- 文章列表或者分页数据的展示
Set
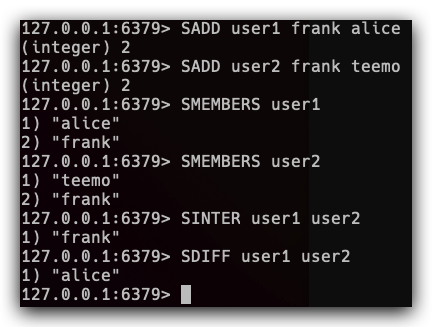
Set是无序集合,并且集合元素是不重复的。并且Set支持查询交集、并集、差集等操作。比如说我们来尝试一下查询共同好友
hash
hash是类似与Map的一种结构
SortedSet
Sorted set 是排序的 Set,去重但可以排序,写进去的时候给一个分数,自动根据分数排序。
有序集合的使用场景与集合类似,但是set集合不是自动有序的,而Sorted set可以利用分数进行成员间的排序,而且是插入时就排序好。所以当你需要一个有序且不重复的集合列表时,就可以选择Sorted set数据结构作为选择方案。
- 排行榜:有序集合经典使用场景。例如视频网站需要对用户上传的视频做排行榜,榜单维护可能是多方面:按照时间、按照播放量、按照获得的赞数等。
- 用Sorted Sets来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
扩展功能
Bitmap :
位图是支持按 bit 位来存储信息,可以用来实现 布隆过滤器(BloomFilter);
HyperLogLog:
供不精确的去重计数功能,比较适合用来做大规模数据的去重统计,例如统计 UV;
Geospatial:
可以用来保存地理位置,并作位置距离计算或者根据半径计算位置等。有没有想过用Redis来实现附近的人?或者计算最优地图路径?
pub/sub:
功能是订阅发布功能,可以用作简单的消息队列。
Pipeline:
可以批量执行一组指令,一次性返回全部结果,可以减少频繁的请求应答。
Lua:
Redis 支持提交 Lua 脚本来执行一系列的功能。
事务:
最后一个功能是事务,但 Redis 提供的不是严格的事务,Redis 只保证串行执行命令,并且能保证全部执行,但是执行命令失败时并不会回滚,而是会继续执行下去。
Stream:
Redis Stream 是 Redis 5.0 版本新增加的数据结构。
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。
而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
数据持久化方式
Redis提供了AOF和RDB两种数据持久化方式,RDB是把内存中的数据集以快照的方式来写入磁盘,实际操作是使用 fork 子进程执行,采用二进制压缩存储,而AOF则是以文本日志的方式记录Redis处理的每一个写入或者删除操作。
RDB 把整个 Redis 的数据保存在单一文件中,比较适合用来做灾备,但缺点是快照保存完成之前如果宕机,这段时间的数据将会丢失,另外保存快照时可能导致服务短时间不可用。
AOF 对日志文件的写入操作使用的追加模式,有灵活的同步策略,支持每秒同步、每次修改同步和不同步,缺点就是相同规模的数据集,AOF 要大于 RDB,AOF 在运行效率上往往会慢于 RDB。
Key失效机制
Reids的key可以设置过期时间,采用主动、被动删除策略,主动即定期随机删除一些过期key,被动则是每次访问的时候删除。
淘汰策略
精选文章 Redis的内存淘汰策略
Redis的内存淘汰策略
我们知道Redis是基于内存的key-value数据库,因为系统的内存大小有限,所以我们在使用Redis的时候可以配置Redis能使用的最大的内存大小。
1、通过配置文件配置
通过在Redis安装目录下面的redis.conf配置文件中添加以下配置设置内存大小。
//设置Redis最大占用内存大小为100M
maxmemory 100mbredis的配置文件不一定使用的是安装目录下面的redis.conf文件,启动redis服务的时候是可以传一个参数指定redis的配置文件的。
2、通过命令修改
Redis支持运行时通过命令动态修改内存大小
//设置Redis最大占用内存大小为100M
127.0.0.1:6379> config set maxmemory 100mb
//获取设置的Redis能使用的最大内存大小
127.0.0.1:6379> config get maxmemory如果不设置最大内存大小或者设置最大内存大小为0,在64位操作系统下不限制内存大小,在32位操作系统下最多使用3GB内存
Redis的内存淘汰
Redis定义了几种策略用来处理这种情况:
- noeviction(默认策略):对于写请求不再提供服务,直接返回错误(DEL请求和部分特殊请求除外)
- allkeys-lru:从所有key中使用LRU算法进行淘汰
- volatile-lru:从设置了过期时间的key中使用LRU算法进行淘汰
- allkeys-random:从所有key中随机淘汰数据
- volatile-random:从设置了过期时间的key中随机淘汰
- volatile-ttl:在设置了过期时间的key中,根据key的过期时间进行淘汰,越早过期的越优先被淘汰
当使用volatile-lru、volatile-random、volatile-ttl这三种策略时,如果没有key可以被淘汰,则和noeviction一样返回错误。

